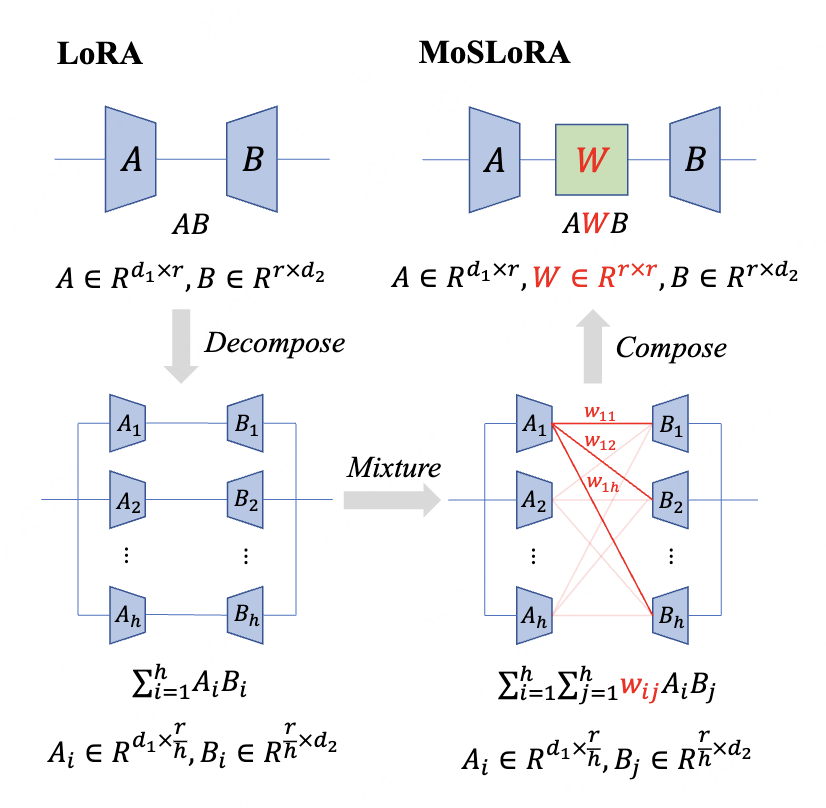
We introduce a subspace-inspired Low-Rank Adaptation (LoRA) method, which is computationally efficient, easy to implement, and readily applicable to large language, multimodal, and diffusion models.
Taiqiang Wu, Jiahao Wang, Zhe Zhao, Ngai Wong
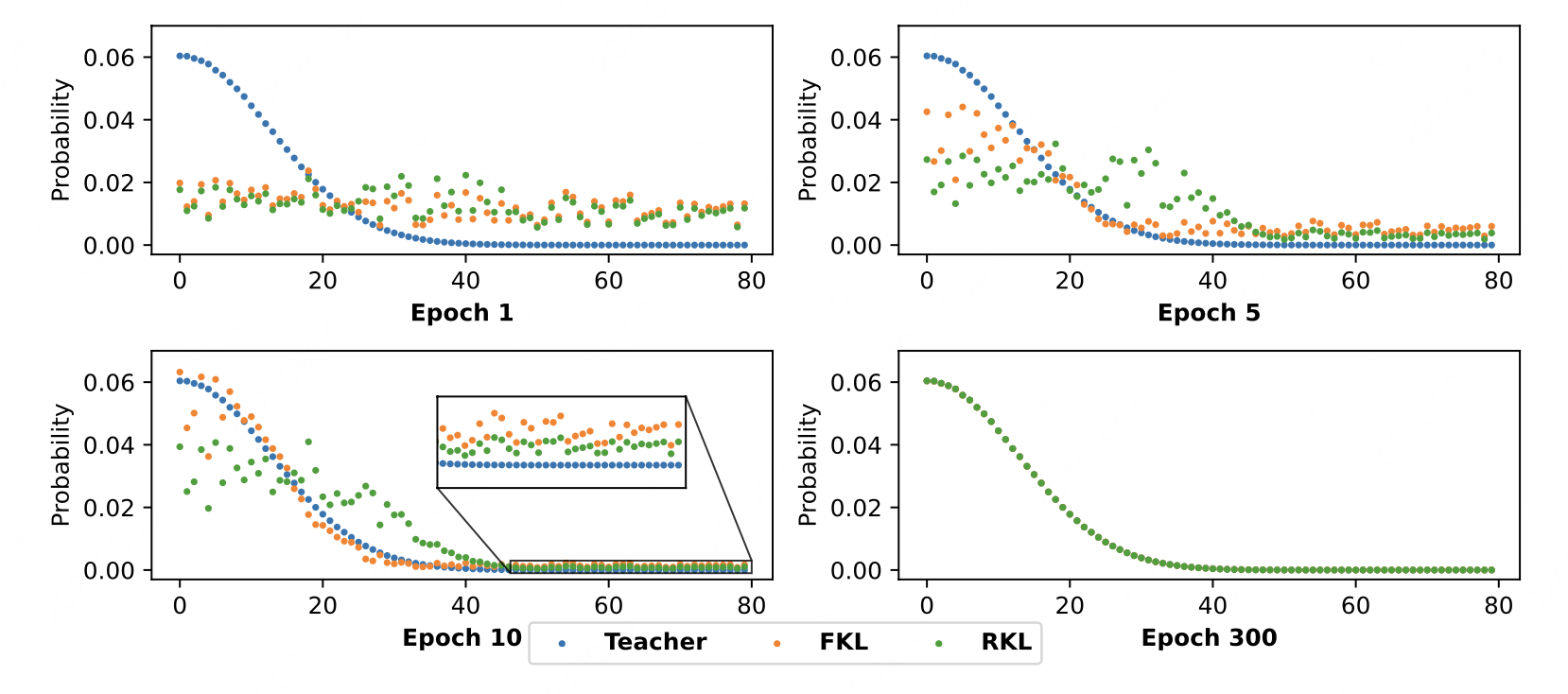
We provide a deeper insight into forward KL and reverse KL in the KD for LLM and then propose a novel AKL based on the analysis.
Taiqiang Wu, Chaofan Tao, Jiahao Wang, Runming Yang, Zhe Zhao, Ngai Wong